

 TEAM IM
TEAM IM
Automatic Redaction in WebCenter - A TEAM IM Webinar
Protecting sensitive data is extremely important for your organization. The release of public records, data breaches, and simple sharing between...
By: Jon Chartrand - Director of Product Management
The concept of sensitive information management is germane to pretty much every business, organization, and public sector outfit in the world. Typically, this sensitive information is classified as “PII” or Personally Identifiable Information – this would be any data which could lead to someone being personally identified and includes things like social security numbers, date of birth, and phone numbers. Other data, often revolving around financial information, includes credit card numbers, bank account numbers, and account balances. All of these data points must be carefully monitored and masked before documents can potentially be made available for distribution – externally or internally. Failure to do so can lead to devastating legal and financial consequences, bankrupting corporations and governments alike. As experts in the field of content management and in bringing order to unstructured data, we felt an obligation to assist our clients with this often expensive and time-consuming effort.
Examples of PII, according to the National Institute of Standards and Technology (NIST)1:
| Name | Street Address | State | Zip Code |
| Telephone Number | Email Address | Social Security Number | Medical Record Number |
| Health Plan Number | Account Number | Account Balance | ACH Number |
| Bank Account | Routing Number | Credit Card Number | CCV Code |
| Driver’s License Number | Passport Number | Taxpayer ID | Date of Birth |
Just these example values represent a staggering amount of data across potentially every piece of content your organization creates, updates, manages, stores, distributes, and archives. The compliance costs required to scour content for this data can be monumental in terms of both dollars and hours. However, these costs can pale in comparison to the costs associated with a data breach. A recent study found that the average total cost of a data breach in the US can exceed $7 million, with an average per-record cost of more than $2002. These are some frightening numbers. So how do we help strengthen your compliance efforts while also reducing your compliance costs? That is the question we asked ourselves several months ago and the answer, we believe, is the TEAM IM Redaction Engine.
We built the Engine to meet three specific needs:
The Redaction Engine is a plugin, or component, for Oracle’s WebCenter Content (WCC) platform. This was done because WCC is a leader in the Enterprise Content Management space and it has direct integrations with powerful scanning solutions, Oracle’s cloud-based platforms, and powerful search options such as Elasticsearch. Other than enabling scanning, the component requires no additional software or hardware to perform its functions against the content in your repository – which is a revolution in the sensitive information arena.
When it comes to assisting with sensitive information compliance, the primary challenge comes in the form of identifying the data in question. Between our efforts with WebCenter Content and with Elasticsearch in the enterprise content management space, we realized that we already have access to every character of every piece of digital content that’s been indexed. What it boils down to is identifying patterns and developing a method for seeking those patterns in the available data. Look again at the table of examples above. Of the 20 data points described, 18 of them (90%!) can easily be identified based on a likely pattern. This is where we started on our efforts.
The Redaction Engine is focused around a primary core – the Pattern Matching Engine. We allow you to craft a series of patterns using both Regular Expressions and Simple Patterns. To identify Social Security Numbers, for example, you’ll need to take into account the common variation which lacks the dashes. You could choose to use two simple patterns if you weren’t interested in specifics of SSN rules:
These would pick up Social Security Numbers but would also incorrectly identify any numeric value which fits this form but doesn’t actually meet certain rules for SSN’s such as that no group of digits can be all zeroes. We could instead craft a regular expression which is much more robust and is designed to meet the rules of SSN’s laid out by the Social Security Administration3:
This is an example of how simple and also how robust the pattern matching can be. These same tactics  can be applied to matching pretty much any other predictably-formatted value. The only question is the depth of complexity you want to apply to the efforts. Given that Regular Expression experts are fairly rare, we also included an expression evaluator in the interface. This provides feedback on your expressions and confirms whether each pattern makes sense to the engine or not.
can be applied to matching pretty much any other predictably-formatted value. The only question is the depth of complexity you want to apply to the efforts. Given that Regular Expression experts are fairly rare, we also included an expression evaluator in the interface. This provides feedback on your expressions and confirms whether each pattern makes sense to the engine or not.
Now that the patterns are configured, WebCenter Content does the heavy lifting during the check-in process of opening the document and extracting the text within so that the document’s contents can be indexed. This indexing means you can search for a word inside the document instead of just the title or metadata. It also means we have a readily available block of extracted text that we can quickly parse against our patterns and identify desired information. Once identified, we simply hand the PDF to an editing library which adds the redaction, burns it into the document, and saves a new copy as a “Redacted Rendition”. The new PDF even remains full-text searchable – it just has the redacted text removed! This is the simplest – and most common – scenario.
Less common but no less important are image-based, or scanned, documents. As paper documents are still a fact of life, we always want to keep an eye on our methods for digitizing that physical content to bring it into the repository. Whether that’s a simple WebCenter Capture setup or some other scanning platform, the important piece is that we get this now-digital item into a managed structure such as WebCenter Content. If your choice is to stick with the WebCenter family, the Redaction Engine is specifically enhanced to work intimately with both Capture and Oracle Forms Recognition (OFR). One of the best examples of this partnership is with content that contains non-digital text, that is, handwriting.
After the paper item is digitized via the scanner and Capture, it’s passed to OFR for processing. This is where we set up “markers” and instruct OFR where to look for characters in a specific location. Even if Oracle Forms cannot interpret the handwriting (via Optical Character Recognition or OCR) it can identify the precise coordinates for the location of the handwriting. Now we simply pass the digitized document and the coordinates to WebCenter Content and the Redaction Engine.
![]()
![]()
In the end we have a perfectly redacted entry even though the text wasn’t readable by a character recognition engine. This means that as long as we can find digital “landmarks” in our document, we can train Oracle Forms Recognition to look for and identify illegible entries and pass those for redaction.
If, however, your solution for scanning physical documents does not include WebCenter Capture or Oracle Forms Recognition, the Redaction Engine is happy to work with those items as well.
 A Bad Fax
A Bad Fax
In fact, any image-based content can be passed through the Redaction Engine as we’ve included an OCR library with the product. This means not only image-based PDFs but native TIFF, JPEG, or GIF files can be processed as well. The Redaction Engine OCR library will process the content item and scan for any machine-readable English text that it can find. Of course, like with any OCR process, there are limitations in terms of language, fonts, and file resolution however the vast majority of modern scanned documents will have no problems being read. If you’re submitting documents sent via fax machine in 1997 and then digitized with a consumer-grade scanner a year later, you could very well run into issues.
Something extra on this front comes from the fact that we’re finding text in these images – search. While WebCenter Content would not ordinarily be able to include these content items in the full text search index, we’ve joined the Redaction Engine with TEAM IM’s Elasticsearch Integration to make this happen. That mean’s any text found when an image or image-based item is passed through the engine is submitted to the Elasticsearch index, making it fully searchable. This means, for example, that a scanned invoice could possibly be found by searching for the vendor name, or the invoice ID, or the invoice total and not just by the metadata that was associated to the item at check-in.
We’ve now covered three specific cases where content can be redacted:
In all cases the Redaction Engine creates a new, specifically-redacted content item that is separate and unique from the original file. The redactions are also “burned in” to the new file ensuring that the underlying text is permanently removed. Both of these steps are taken to first ensure that no data is lost for the redaction process and, second, to simultaneously ensure that redacted items are secure in terms of information removal.
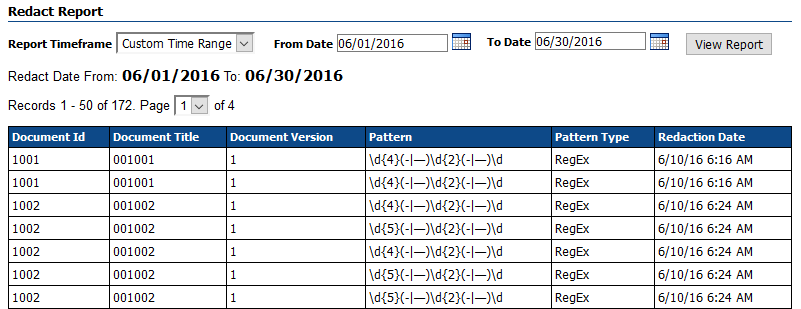
The last piece of what we have come to call “responsible redaction” is the auditing capability of the Redaction Engine. The product keeps a record of every redaction performed – not just at a document level but at the redaction level. A single content item with several redactions has every individual redaction logged, including the specific pattern that was matched in each case. Redaction Reports can be generated for any date range desired and can be exported as a Microsoft Excel document. This exported document can now be stored as a managed record in WebCenter Content or maintained elsewhere for legal purposes. The goal in all cases is simply to provide as much transparency as possible into a process that is built to, well, do the exact opposite!
The Redaction Engine is not only about helping to lessen the burden on businesses that have to manually parse, identify, and redact sensitive information but to also bolster those on-going information compliance efforts and keep trouble from finding the front door. As we’ve worked on this effort, I’ve come to find a much greater appreciation for the efforts that must be undertaken to try and keep our information safe and secure. As a group, we’re incredibly pleased to be able to offer a solution that could very well save you and your business time, money, and headaches.
1 “Guide to Protecting the Confidentiality of Personally Identifiable Information (PII)”, NIST, April 2010
2 “2016 Cost of Data Breach Study: United States”, Ponemon Institute, June 2016
3 “Validating Social Security Numbers through Regular Expressions”, Rion Williams, Codeproject.com, Sep 2013
Protecting sensitive data is extremely important for your organization. The release of public records, data breaches, and simple sharing between...

It isn’t exactly revolutionary to say that advancing technology has massively changed the ways in which business operations are conducted. From...
Raoul Miller – Enterprise Architect